
Distributed processing, a powerful method of task distribution, involves spreading processing tasks across multiple nodes in a network.
Distributed processing is an excellent strategy for data communication because it offers improved performance and scalability, quicker data processing, high availability, and fault tolerance. Performance is only one aspect of it; it also provides cost-effectiveness, geographical distribution to reduce latency, load balancing in distributed systems, adaptability, and modularity.
With real-time data processing Plus energy efficiency, it ensures that data-driven applications run smoothly and efficiently. Moreover, its inherent redundancy and data backup feature protect your valuable data, making it a game-changer for modern data-driven environments.
In this article, we will delve into the incredible benefits of distributed processing in data communication. By exploring real-world examples, we will illustrate how this innovative technique is reshaping the landscape of data processing.
Table of Contents
ToggleDefinition of Distributed Processing in Data Communication:
Distributed processing cleverly divides processing tasks among numerous nodes within a network. This smart allocation enables scalability, accessibility, outstanding performance, reliability, and cost-effectiveness in data communication. As a result, data-driven applications significantly enhance their functionality, dependability, and adaptability.
Importance of Distributed Processing:
The demand to analyze massive volumes of data at an unheard-of rate is constantly expanding in today’s fast-paced, data-centric environment or sourrandings.
The escalating demand is difficult for conventional centralized processing systems to handle. However, distributed processing, which effectively distributes the processing burden across numerous nodes, emerges as the best option. Data-driven applications’ performance, dependability, and adaptability are significantly increased by this intentional distribution.
Key Takeaways:
- Distributed processing in data communication offers numerous advantages, including enhanced performance, scalability, faster data processing, and high availability. It also provides cost-effectiveness, reduced latency through geographical distribution, load balancing, and real-time data processing.
- The flexibility plus modularity of distributed systems allow for seamless scalability and dynamic resource allocation. Energy efficiency and inherent data redundancy ensure data integrity and backup in case of node failures.
- Despite its benefits (advantages), distributed data processing comes with challenges, such as complexity in troubleshooting and managing interconnected computers. Data security and vulnerability to attacks are concerns, along with compatibility challenges and data consistency issues.
- Properly understanding and addressing these challenges is essential or important for maximizing the benefits of distributed processing while minimizing potential drawbacks in data communication.
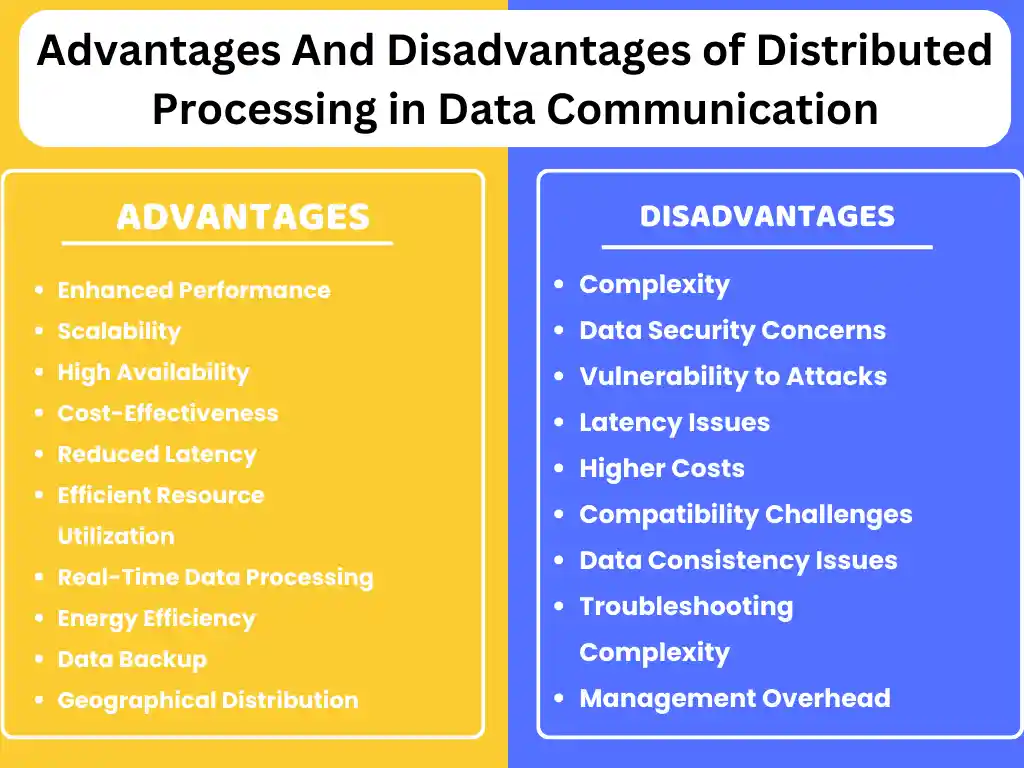
Advantages of Distributed Processing in Data Communication:
Enhanced Performance and Scalability:
Distributed processing excels in enhancing performance by distributing the processing load across multiple nodes. This proves especially beneficial for applications dealing with extensive data volumes or experiencing fluctuating traffic patterns. By parallelizing data processing across nodes, the overall processing time is significantly reduced.
Real-World Application Example:
E-commerce platforms effortlessly manage high transaction volumes during peak periods, ensuring seamless shopping experiences for customers.
High Availability and Fault Tolerance:
A significant advantage of distributed processing lies in improving application availability through distributed data and processing across multiple nodes. Should one node fail, others continue processing, ensuring uninterrupted service and minimizing downtime.
Real-World Application Example: Online banking platforms remain operational even during server failures, safeguarding customers’ access to critical financial services.
Cost-Effectiveness:
Distributed processing offers a cost-efficient alternative to centralized systems by utilizing less powerful and more cost-effective nodes. Businesses achieve impressive data processing capabilities without exorbitant hardware investments.
Real-World Application Example: Startups and small enterprises leverage distributed processing to meet their data needs while staying within budget constraints.
Geographical Distribution and Latency Reduction:
Distributed processing strategically distributes applications and data across multiple geographical locations, minimizing data latency and ensuring faster response times, regardless of the user’s location.
Real-World Application Example: Content delivery networks (CDNs) utilize distributed processing to deliver content from servers closest to users, reducing latency and optimizing website load times.
Load Balancing in Distributed Systems:
Distributed processing facilitates load balancing across multiple nodes, optimizing resource utilization and preventing individual nodes from becoming overwhelmed. This balanced distribution enhances system performance and reliability.
Real-World Application Example: Video streaming services leverage distributed processing to manage high video requests, delivering uninterrupted streaming experiences to users.
Distributed systems’ adaptability and modularity:
The flexibility and modularity of distributed systems is unparalleled. Nodes can be effortlessly added or removed as needed, allowing seamless scalability based on evolving requirements.
Real-World Application Example: Cloud computing platforms provide flexible resource allocation, enabling businesses to dynamically scale processing power as demands evolve.
Real-Time Data Processing:
Distributed processing supports real-time data processing, enabling applications to react swiftly to events as they occur.
Real-World Application Example: Stock trading platforms process market data in real-time, empowering traders to make rapid decisions for optimal results.
Energy Efficiency in Distributed Processing:
Distributed processing boasts higher energy efficiency than centralized processing, as nodes can be powered down when idle, contributing to energy conservation.
Real-World Application Example: Large data centers adopt distributed processing to optimize energy usage, reducing their carbon footprint.
Inherent Redundancy and Data Backup:
Distributed systems inherently provide data redundancy as data is stored across multiple nodes. This redundancy ensures data integrity and offers data backup in case of node failures.
Real-World Application Example: Enterprises replicate data across multiple servers to protect against data loss and ensure continuous access to critical information.
Disadvantages of Distributed Data Processing in Data Communication:
While distributed data processing offers many benefits or Advantages, it also presents challenges in data communication.
Complexity:
Troubleshooting, designing, and administering interconnected computers can become complex in distributed data processing. Managing data synchronization poses challenges, leading to potential errors and data updates in the wrong order.
Data Security:
Security becomes a concern in distributed systems as unauthorized access to one connected computer can jeopardize the entire network’s performance and lead to data loss.
Vulnerability to Attacks:
Distributed processing systems are more susceptible to security attacks compared to centralized processing. The distribution of data across multiple nodes makes it harder to protect and defend against potential threats.
Latency:
The transmission of data between nodes in a distributed system can cause delays in processing requests, impacting the system’s overall performance.
Higher Costs:
Distributed data processing can be more expensive (costly) than centralized processing, especially when nodes (smart devices) are located in multiple geographical locations, requiring additional infrastructure and resources.
Compatibility Challenges:
Integrating distributed processing systems with existing ones can be difficult due to variations in hardware and software used by different nodes.
Data Consistency:
Data consistency is a major difficulty in distributed systems. Data may be updated at different times on different nodes (smart devices), resulting in potential disparities and data integrity issues.
Troubleshooting Complexity:
Identifying & resolving problems in a distributed system can be complicated. Issues may arise from any of the interconnected nodes or the network itself, making troubleshooting a time-consuming task.
Management Overhead:
Managing distributed systems necessitates monitoring and controlling several nodes, which increases administrative cost when compared to centralized systems.
Wrap Up
To summarize or sum up the distributed data processing is a powerful and advantageous technique to data communication. It improves performance, scalability, and data processing speed. The system is highly available and fault tolerant, making it suitable for modern data-driven scenarios. Its versatility and real-time processing capabilities are essential for effective operations, and its energy efficiency and data redundancy offer additional benefits or advantages to enterprises.
However, remote data processing is not without its difficulties. Troubleshooting and managing networked systems can be difficult, and guaranteeing data consistency and security necessitates close scrutiny. Despite these obstacles, the benefits or Advantages of distributed processing in Data communication make it indispensable for streamlining data communication and redefining information consumption.
Distributed data processing will continue to evolve and improve as technology advances, assisting organizations in gaining a competitive edge & meeting the needs of a data-driven world. This innovative technique shapes the future of data communication, paving the way for more efficient and sophisticated applications.
Thank you for joining us on this journey to learn about the advantages of distributed processing in data communication.
People Also Read:
FAQs: People Also Read
What is distributed processing and its advantages?
Distributed processing is a powerful approach that optimizes data communication by distributing processing tasks across multiple nodes in a network. The advantages it offers encompass improved performance, scalability, swift data processing, high availability, fault tolerance, cost-effectiveness, minimized latency, load balancing, adaptability, and modularity. It also supports real-time data processing and energy-efficient operations with inherent data redundancy for enhanced data protection.
What are the advantages and disadvantages of distributed data processing?
Advantages of Distributed Data Processing:
- Enhanced performance
- Scalability
- High availability
- Cost-effectiveness
- Reduced latency
- Efficient resource utilization
- Real-time data processing
- Energy efficiency
- Data backup
All these benefits contribute to bolstered data integrity.
However, it also presents challenges such as troubleshooting complexity, data consistency issues, security concerns, vulnerability to attacks, potential latency, higher costs, compatibility challenges, and increased management overhead.
What are three advantages of distributed processing?
Three advantages of distributed processing are enhanced performance through load balancing, improved scalability to handle growing data volumes, and real-time data processing capabilities for swift reactions to events.
What are the main advantages of distributed systems?
The main advantages of distributed systems are improved performance to handle diverse data processing demands, seamless scalability for evolving requirements, high availability to ensure uninterrupted services, fault tolerance to minimize downtime, cost-effectiveness through efficient resource utilization, and adaptability for dynamic environments.
What is the advantage of distributed data?
The advantage of distributed data lies in its inherent redundancy and data backup. This ensures data integrity and continuous access to critical information, even in the event of node failures.
What are two disadvantages of distributed processing?
Two disadvantages of distributed processing are the complexity in troubleshooting interconnected computers, which may span across different locations, and the potential challenges in maintaining consistent data updates on different nodes.
What is the main advantage of distributed data storage?
The main advantage of distributed data storage is its inherent redundancy, which provides reliable data backup and protection against data loss in case of node failures.
What are the advantages of data processing?
The advantages of data processing include improved performance through efficient task distribution, scalability to handle growing data needs, high availability and fault tolerance for uninterrupted operations, cost-effectiveness with optimized resource utilization, real-time data processing for swift decision-making, and energy efficiency to conserve power.
Which of the following is a disadvantage of distributed data processing?
One of the disadvantages of distributed data processing is the complexity in troubleshooting and managing interconnected computers distributed across various nodes and networks.
What are examples of distributed processing?
Examples of distributed processing include e-commerce platforms efficiently managing high transaction volumes during peak periods, online banking platforms providing uninterrupted access to critical financial services, content delivery networks delivering web content from nearby servers to reduce latency, cloud computing platforms offering flexible resource allocation, and stock trading platforms processing real-time market data to enable quick decision-making for optimal results.
I get pleasure from, result in I discovered exactly what I
was having a look for. You have ended my 4 day long hunt!
God Bless you man. Have a great day. Bye